
Athento Cloud has a Service Continuity Policy, which is implemented in the event of cloud service outages.
The Service Continuity Policy includes rules, procedures and tools through which Athento improves its response capacity when critical system failures occur, as well as its resilience to major incidents, preventively ensuring possible failures and improving the times in which the team is able to respond to incidents.
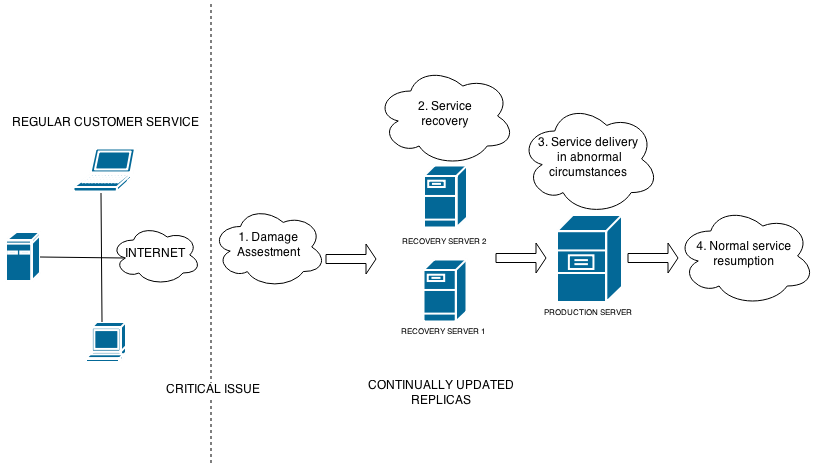
What happens after a system failure?
The Service Continuity Plan is activated, which consists of 4 major stages:
- Initial response: Damage assessment and determination of appropriate human and technical incident management teams.
- Service recovery: The service is restored, either in the original instance (if deemed relevant and possible in a short period of time) or by enabling one of the existing replicas of the system.
- Provision of service under abnormal circumstances: Service is restored, but is not provided under normal conditions. In our case, temporary measures may include relocating services to another site or using spare replicas. These are temporary measures to provide limited service until normal service can be resumed.
- Resumption of service in normal conditions: The original system and/or the replica is reestablished in the same conditions of architecture, bandwidth, etc. that existed in the original service. In this way, the service returns to the normal service status, prior to the occurrence of the incident.
The main features of our continuity of service policy are highlighted below:
- Athento performs replications of functional instances in production.
- These replicas are stored in different data centers.
- A mirror will always be available for the customer to access the service in case of critical incidents.
- The system has a proxy server that will always redirect to the production server.
Comments
0 comments
Please sign in to leave a comment.