
In Athento it is possible to generate individual documents from a batch of documents loaded in a single file (for example a pdf with 10 simple notes in the same file), dividing the batch by as many individual documents as there are.
To do this, the following steps must be followed:
1. Activate the Extract OCR operation in the space where the batches of documents are to be loaded.
To activate OCR extraction, see article How to extract OCR from a document?
2. Activate the operation to perform the classification of the documents.
The operation is: Classifier by Fuzzy Text Similarity
The parameters to configure in the operation are:
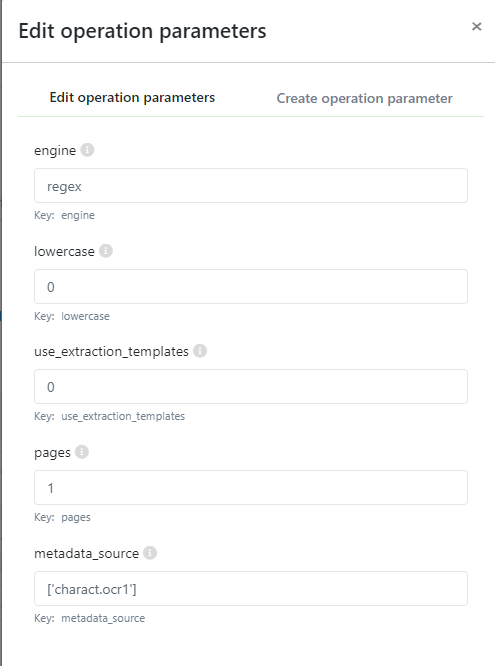
To configure forms for sorting see article: How to configure forms for sorting documents
3. Activate the operation that performs the splitting of documents.
The operation is: Split document by pages classified
Within the parameters, you can indicate the space where the individual documents generated from the batch will be created.
Comments
0 comments
Please sign in to leave a comment.