
In this article, we will explain how it is possible by using different extraction mechanisms, to obtain values from the title of a document or file name to fill in our fields.
For example, we have a case where the document name contains different data that we would like to extract, such as the person's ID, his worker code, and the center where he works (also coded).
The name of our document or file is: 53964230C-1308-102.pdf
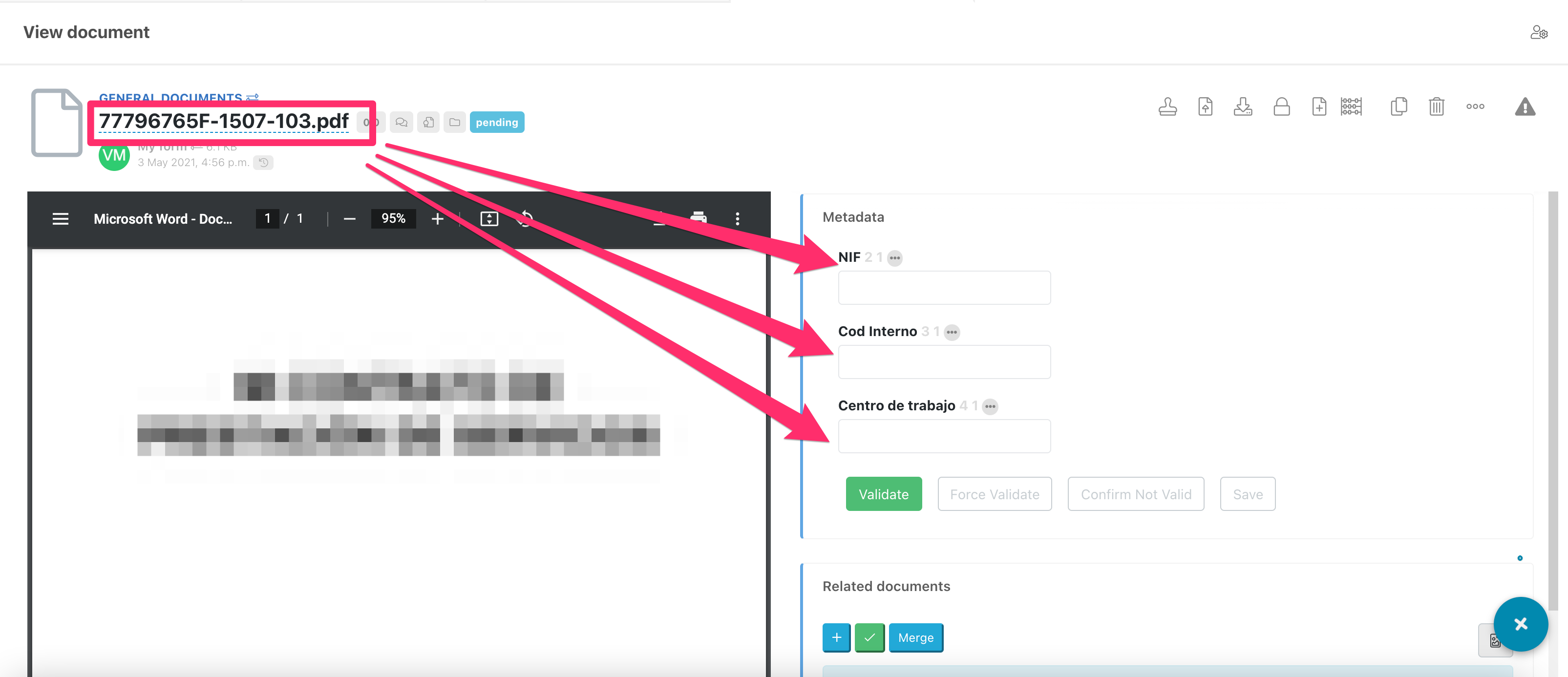
Extracting the ID number with a regular expression
To extract the ID number from a title like 53964230C-1308-102.pdf, we can use a regular expression.
Go to the administration or configuration of the field. From the extraction options:
- Extract from: Filename
- Extraction regular expression:
[0-9]{8}[A-Z]{1}
You can use the pipe | character to separate several expressions.
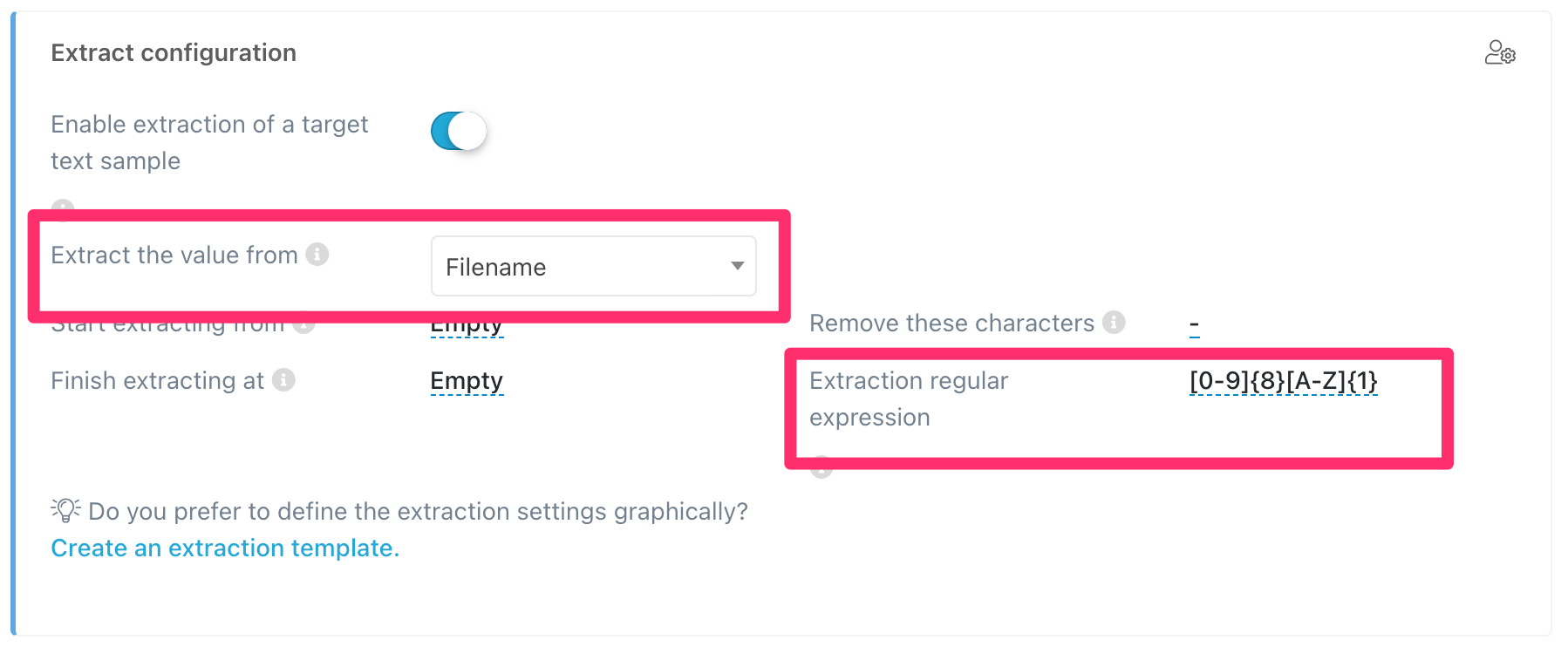
Extracting the worker's code and clearing the field of unwanted characters
In this case, what we want is to keep the numeric value that appears after the ID number and that will be delimited by dashes. -
53964230C-1308-102.pdf
We use again a regular expression in the Internal Cod field configuration.
- Extract from: Filename
- Extraction regular expression:
-[0-9]{4}-.
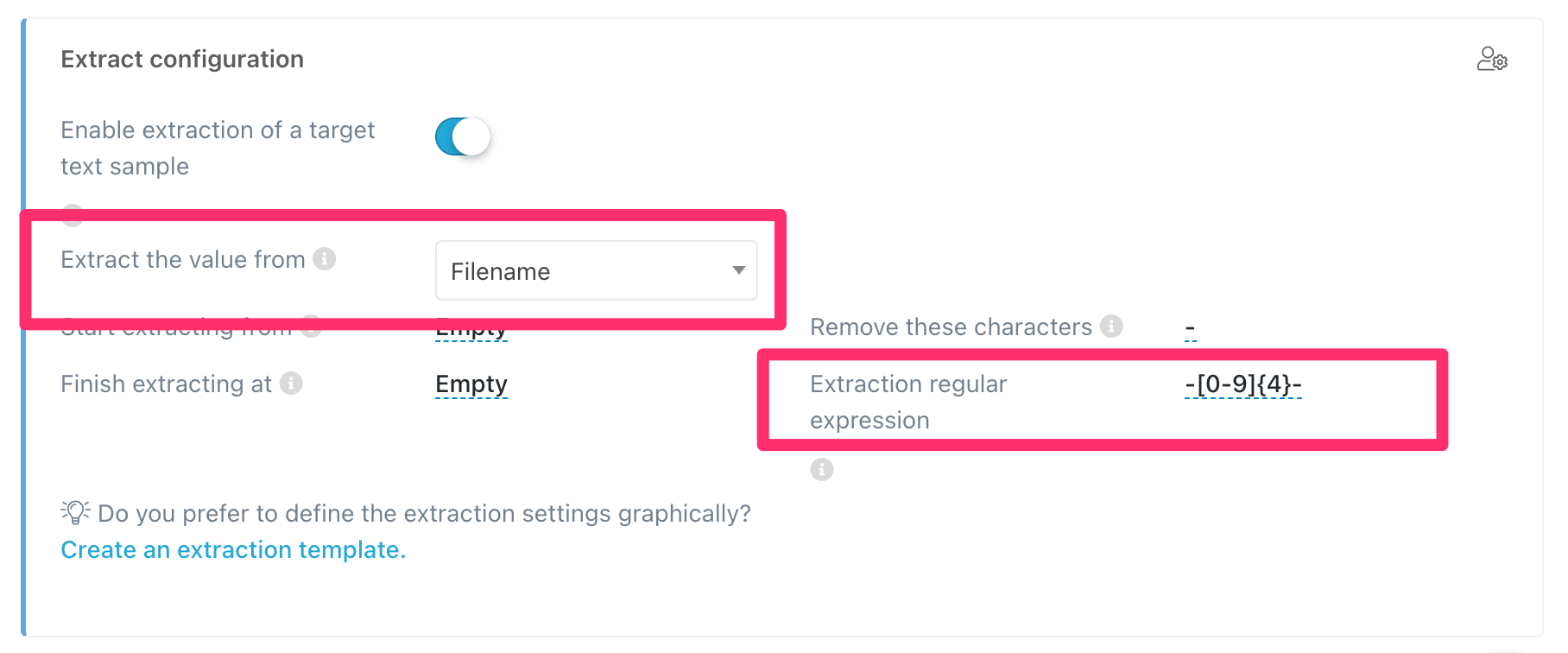
This expression will give us the data including the dashes. If we want to remove them, we can use:
- Remove these characters:
-
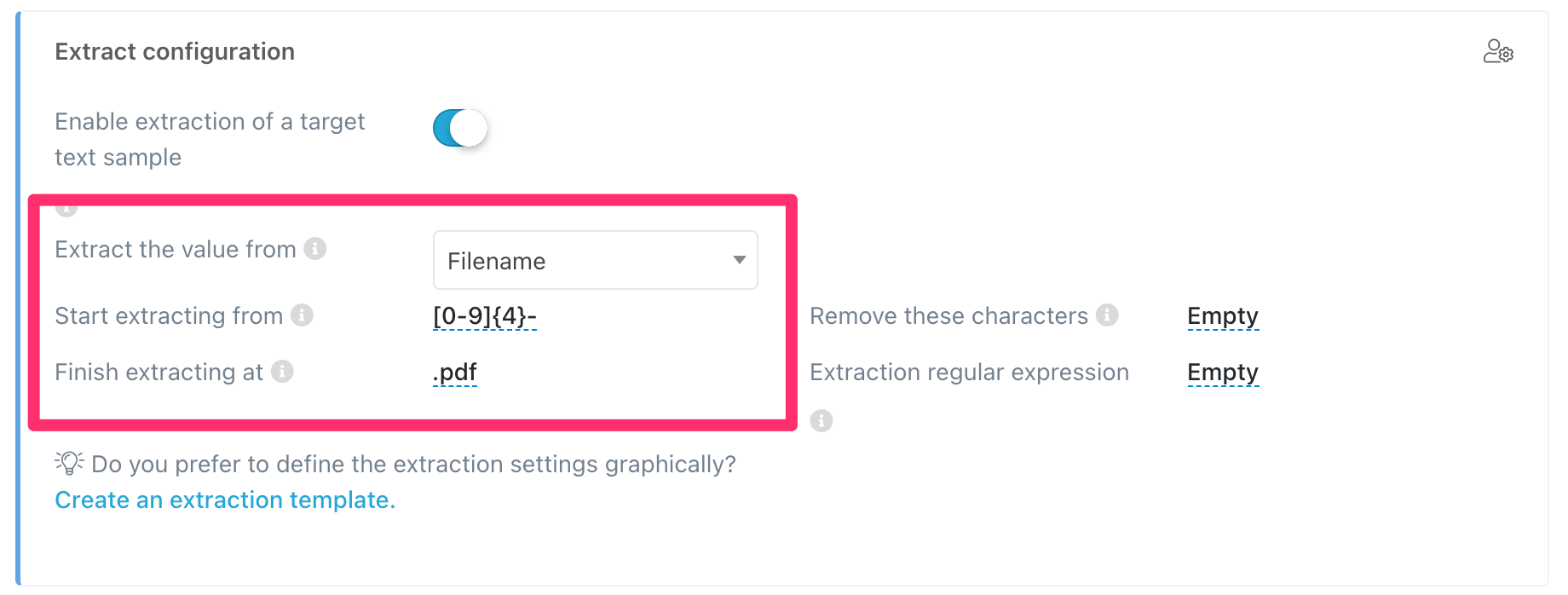
Obtaining the work center with a prefix and an a sufix expression
Finally, to get the last piece of information 53964230C-1308-102.pdf from the file name, you can use a start and an end expression.
- Extract from: Filename
- Start extracting from:
[0-9]{4}- - Finish extracting at:
.pdf
In this case, what you are telling Athento is to look for 4 digits followed by a hyphen and from there take whatever it finds until it gets to the file extension.
Comments
0 comments
Please sign in to leave a comment.