
Athento SE is a document manager focused on facilitating the automation of tasks on documents, for this reason it includes from its first versions with libraries for document analysis and the configuration of classification and metadata extraction functionalities. The following is a description of some of the functionalities it allows. For more details, please consult soporte@athento.com for your case, as there are many more possibilities:
Translated with www.DeepL.com/Translator (free version)
Prediction of metadata in documents
This functionality allows, through an operation applied to a document or through the extract value option of a metadata, to predict such metadata by means of Machine Learning techniques.
In order to use this, a Machine Learning model had to be created and trained beforehand (currently everything is done from the Athento interface itself, in the "Data Science" tab of the form type).
The following image shows the typical case of the Iris dataset where Athento includes the capabilities to predict the value of the class according to the rest of the input values:
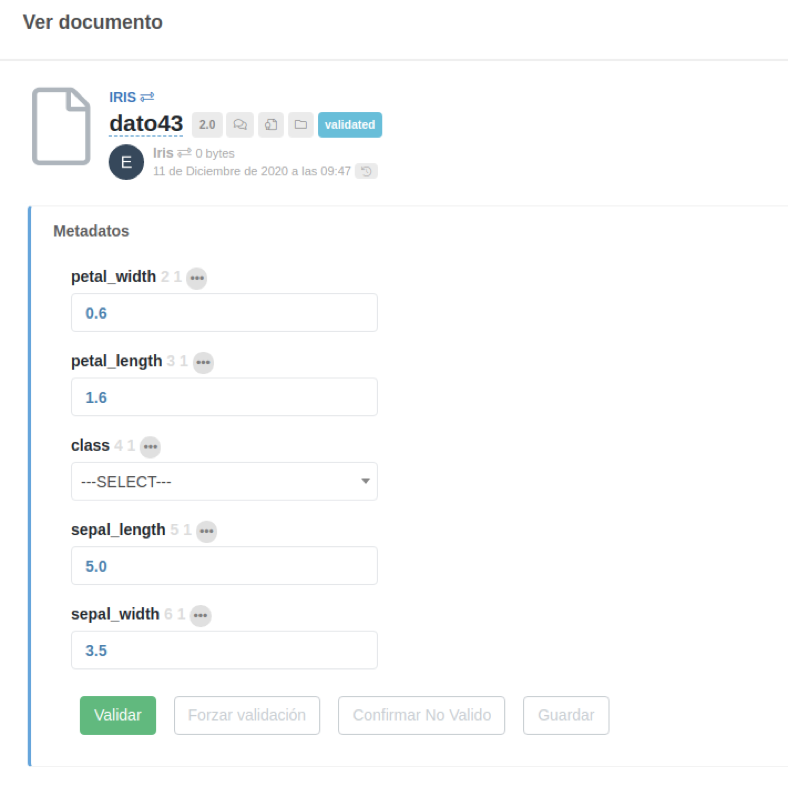
Currently (end of 2020) it can only be applied to numeric or Choice type fields. In the future we want to extend it to fields such as Text type, MultiChoice, etc.
This ML feature is only executed if it is enabled in the Athento advanced manager. By default it is disabled.
Logistic Regression, Linear Regression and K-nearest neighbors models are currently available.
Document information
By training an ML model for metadata prediction, this also allows us to generate graphs that give us some information about our documents and the ML model itself:
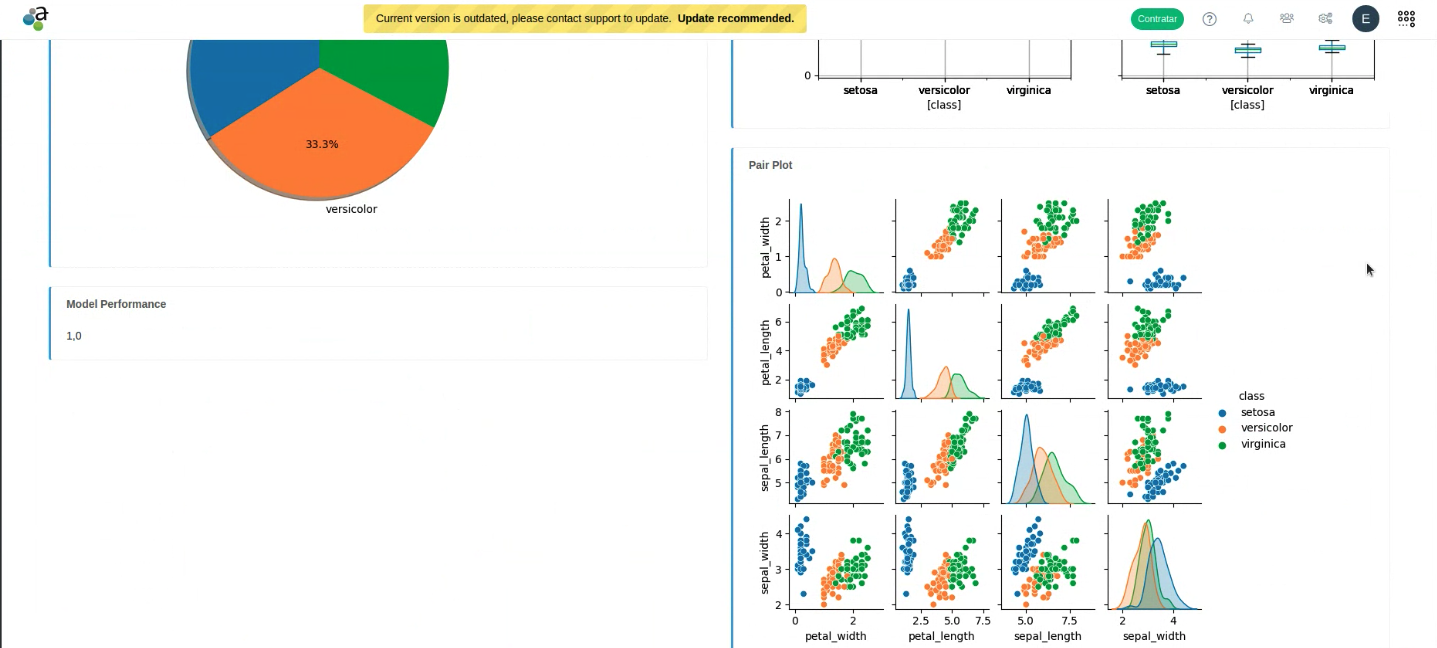
Prediction of the next state in a life cycle
An operation is available that allows you to predict and change the status of a document based on the previously existing history. In the future this functionality will be transparent to users.
Classification of emails
In a space with a mailbox configured for document upload, it is possible to activate the classification of emails based on keywords. Although, since emails have many words that generate false positives, this functionality requires specific training in most cases.

Comments
0 comments
Please sign in to leave a comment.